初试强化学习 - Gym框架搭建倒立摆实验
初试强化学习 - Gym框架搭建倒立摆实验
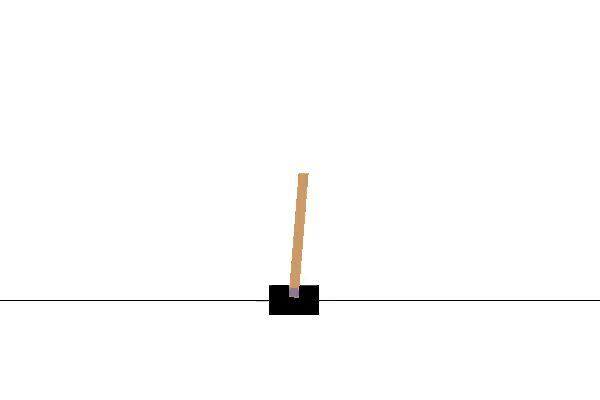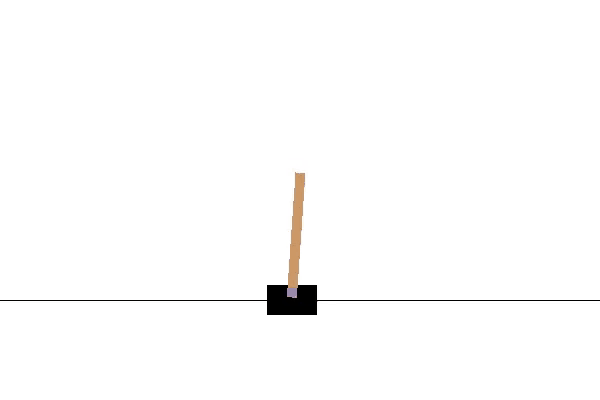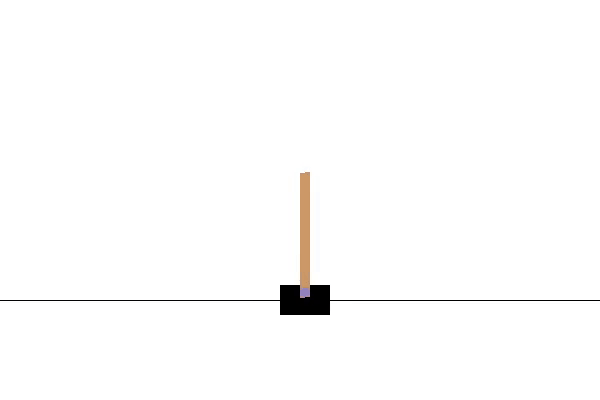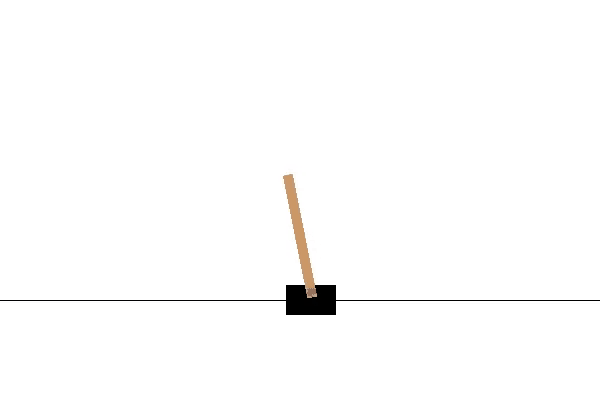
摘要:
OpenAI Gym是一款用于研发和比较强化学习算法的工具包,本文主要介绍Gym仿真环境的搭建、功能和工具包的使用方法,并详细介绍其中的经典控制问题中的倒立摆(CartPole)问题。最后针对强化学习方法解决倒立摆问题给出自己的理解,并给出了相应的完整python代码示例和解释。
一些资源:
- OpenAI Gym官方docs:Documentation
- OpenAI Gym官方提供的仿真环境:Environments
- DQN解决倒立摆问题:博主自己的github仓库
Gym框架安装及简单demo示例
Anaconda环境
为了方便环境的管理,养成良好的习惯,强烈建议学习和使用Anaconda环境!
Anaconda的安装请参考这篇文章:Anaconda3安装及配置
利用Anaconda新建虚拟环境
首先创建一个python3.6的Anaconda虚拟环境:
conda create --name gymTest python=3.6Anaconda创建虚拟环境的格式为:conda create –-name 你要创建的名字 python=version。比如我创建的虚拟环境名字为gymTest(你可以用自己的环境名), 用jpython版本号为3.6
随后激活这个环境:
- Linux,OS X:
source activate gymTest- Windows:
activate gymTest激活环境后,你在该终端的任何操作仅会影响到该虚拟环境,对本地环境不造成影响。随后强化学习代码中可能需要用到gym、tensorflow等工具包,都只需要在该虚拟环境下安装即可。
需要进一步了解Anaconda使用方法的可以参考这篇文章:Anaconda常用命令大全
安装Gym
上一步已经安装并激活了一个虚拟环境gymTest, 在这一步要应用,首先终端cd到想要安装gym包的目录下(根据自己电脑环境选取),gym框架的安装非常简单:
step 1:
git clone https://github.com/openai/gym.gitstep 2:
cd gymstep 3:
pip install -e .[all]or just:
pip install gym激活一个小车倒立摆系统
为方便代码的调试和内容注释等,推荐使用jupyter lab或jupyter notebook编写代码,jupyter Notebook是基于网页的用于交互计算的应用程序,其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。当然,直接在终端使用python也可以,下面我们在终端使用python显示一个倒立摆模型:
python #在虚拟环境的终端键入python#激活python后按以下顺序分别键入代码
import gym
env = gym.make(‘CartPole-v0’)
env.reset()
env.render()通过上面的步骤,我们可以看到一个小车倒立摆系统,如下图所示:
注:
本文后面的内容将使用jupyter notebook进行代码编写和调试,当然你可以在python IDE中自己配置,或者跟本文一样使用jupyter notebook,其安装步骤如下:
activate gymTestpip3 install jupyterjupyter notebook #启用jupyter notebook, 默认端口是http://localhost:8888, 直接网页登陆即可其实在哪个环境下安装jupyter都无所谓,在网页端可以直接切换虚拟环境。
具体的jupyter notebook安装和使用可以参考这篇文章:Jupyter Notebook介绍、安装及使用教程
OpenAI Gym仿真环境介绍
简单来说OpenAI Gym提供了许多问题和环境(或游戏)的接口,而用户无需过多了解游戏的内部实现,通过简单地调用就可以用来测试和仿真。接下来以经典控制问题CartPole-v0为例,简单了解一下Gym的特点,以下代码来自OpenAI Gym官方文档
import gym
env = gym.make('CartPole-v0')
env.reset()
for _ in range(1000):
env.render()
env.step(env.action_space.sample()) # take a random action
env.close()
以上代码中可以看出,gym的核心接口是Env。作为统一的环境接口,Env包含下面几个核心方法:
- reset(self):重置环境的状态,返回观察。
- step(self, action):推进一个时间步长,返回observation, reward, done, info。
- render(self, mode=‘human’, close=False):重绘环境的一帧。默认模式一般比较友好,如弹出一个窗口。
- close(self):关闭环境,并清除内存。
Observation
在上面代码中使用了env.step()函数来对每一步进行仿真,在Gym中,env.step()会返回 4 个参数:
- 观测 Observation (Object):当前step执行后,环境的观测(类型为对象)。例如,从相机获取的像素点,机器人各个关节的角度或棋盘游戏当前的状态等;
- 奖励 Reward (Float): 执行上一步动作(action)后,智能体( agent)获得的奖励(浮点类型),不同的环境中奖励值变化范围也不相同,但是强化学习的目标就是使得总奖励值最大;
- 完成 Done (Boolen): 表示是否需要将环境重置 env.reset。大多数情况下,当 Done 为True 时,就表明当前回合(episode)或者试验(tial)结束。例如当机器人摔倒或者掉出台面,就应当终止当前回合进行重置(reset);
- 信息 Info (Dict): 针对调试过程的诊断信息。在标准的智体仿真评估当中不会使用到这个info,具体用到的时候再说。
总结来说,这就是一个强化学习的基本流程,即”agent-environment loop“,在每个时间点上,智能体(可以认为是你写的算法)选择一个动作(action),环境返回上一次action的观测(State)和奖励(Reward),用图可以表示为:
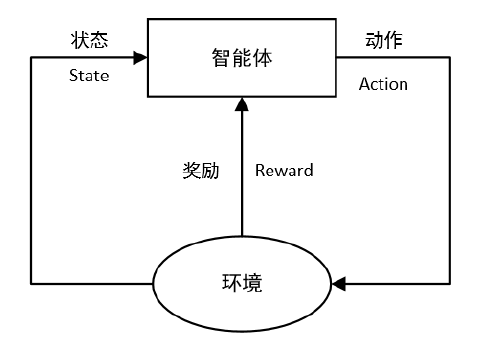
Spaces
在前面的例子中每次执行的动作(action)都是从环境动作空间中随机进行选取的env.action_space.sample(),在 Gym 的仿真环境中,有运动空间 action_space 和观测空间 observation_space 两个指标,程序中被定义为 Space类型,用于描述有效的运动和观测的格式和范围。下面是一个代码示例:
import gym
env = gym.make('CartPole-v0')
print(env.action_space)
#> Discrete(2)
print(env.observation_space)
#> Box(4,)从程序运行结果可以看出:
action_space是一个离散Discrete类型,从discrete.py源码可知,范围是一个{0,1,…,n-1} 长度为 n 的非负整数集合,在CartPole-v0例子中,动作空间表示为{0,1}。observation_space是一个Box类型,从box.py源码可知,表示一个 n 维的盒子,所以在上一节打印出来的observation是一个长度为 4 的数组。数组中的每个元素都具有上下界。
“CartPole-v0”模型仿真过程
在 Gym 仿真中,每一次回合开始,需要先执行 reset() 函数,返回初始观测信息,然后根据标志位 done 的状态,来决定是否进行下一次回合。所以更恰当的方法是遵守 done 的标志,同样我们可以参考OpenAI Gym官方文档中的代码如下
import gym
env = gym.make('CartPole-v0')
for i_episode in range(20):
observation = env.reset()
for t in range(100):
env.render()
print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} timesteps".format(t+1))
break
env.close()在 CartPole-v0 模型中,当 done 为真时,表示倒立摆控制失败,此阶段 episode 结束。可以计算每 episode 的回报就是其坚持的 t+1 时间,坚持的越久回报越大,在上面算法中,agent 的行为选择是随机的,平均回报为20左右。
DQN算法解决倒立摆问题
DQN算法基础原理
DQN是强化学习的经典算法,有能力的同学可以直接从这个算法开始入手接触强化学习,DQN原理这部分内容建议看以下这系列博客,博主已经介绍得非常详细了:
DQN(一)DQN与增强学习
DQN(二)增强学习和MDP
DQN(三)价值函数和Bellman方程
DQN(四)动态规划和Q-learning
DQN(五)深度解读DQN算法
DQN(六)DQN的各种改进
DQN(七)连续控制DQN算法-NAF
DQN(实践)150行代码实现DQN算法玩CartPole
DQN算法在倒立摆模型上的应用
博主利用 jupyter notebook 加上 Anaconda 搭建的虚拟环境,其中需要用到tensorflow中简单的网络进行训练,需要自行安装tensorflow,方法也很简单:
activate / source activate gymTest #根据平台激活虚拟环境conda install tensorflow==1.14 #如果要安装指定版本的tensorflow,在后面加上==版本,如装1.14版本的具体代码如下:
"""
@ Author: Zachary Deng
@ Date: 2021/1/5
@ Brief: 使用 DQN 算法训练CartPole-v0
"""
import random
import gym
import numpy as np
from tensorflow.keras import models, layers
env = gym.make('CartPole-v0') # 创建倒立摆模型
STATE_DIM, ACTION_DIM = 4, 2 # State 维度 4, Action 维度 2
model = models.Sequential([
layers.Dense(64, input_dim=STATE_DIM, activation='relu'),
layers.Dense(20, activation='relu'),
layers.Dense(ACTION_DIM, activation='linear')
]) # 简单的MLP
model.summary()def generate_data_one_episode():
'''生成单次游戏的训练数据'''
x, y, score = [], [], 0
obs = env.reset()
while True:
action = env.action_space.sample()
x.append(obs)
y.append([1,0] if action == 0 else [0,1])
obs, reward, done, info = env.step(action)
score += reward
if done:
break
return x, y, score
def generate_training_data(expected_score=100):
'''生成N次游戏的训练数据,并进行筛选,选择 > 100 的数据作为训练集'''
data_X, data_Y, scores = [], [], []
for i in range(10000):
x, y, score = generate_data_one_episode()
if score > expected_score:
data_X += x
data_Y += y
scores.append(score)
print('dataset size: {}, max score: {}'.format(len(data_X), max(scores)))
return np.array(data_X), np.array(data_Y)data_X, data_Y = generate_training_data()
model.compile(loss='mse', optimizer='adam')
model.fit(data_X, data_Y, epochs=5)
model.save('CartPole-v0-nn.h5')saved_model = models.load_model('CartPole-v0-nn.h5') # 加载模型
env = gym.make("CartPole-v0") # 加载游戏环境
for i in range(5):
obs = env.reset()
score = 0
while True:
time.sleep(0.01)
env.render() # 显示画面
action = np.argmax(saved_model.predict(np.array([obs]))[0]) # 预测动作
obs, reward, done, info = env.step(action) # 执行这个动作
score += reward # 每回合的得分
if done: # 游戏结束
print('using nn, score: ', score) # 打印分数
break
env.close()最终的训练效果展示:
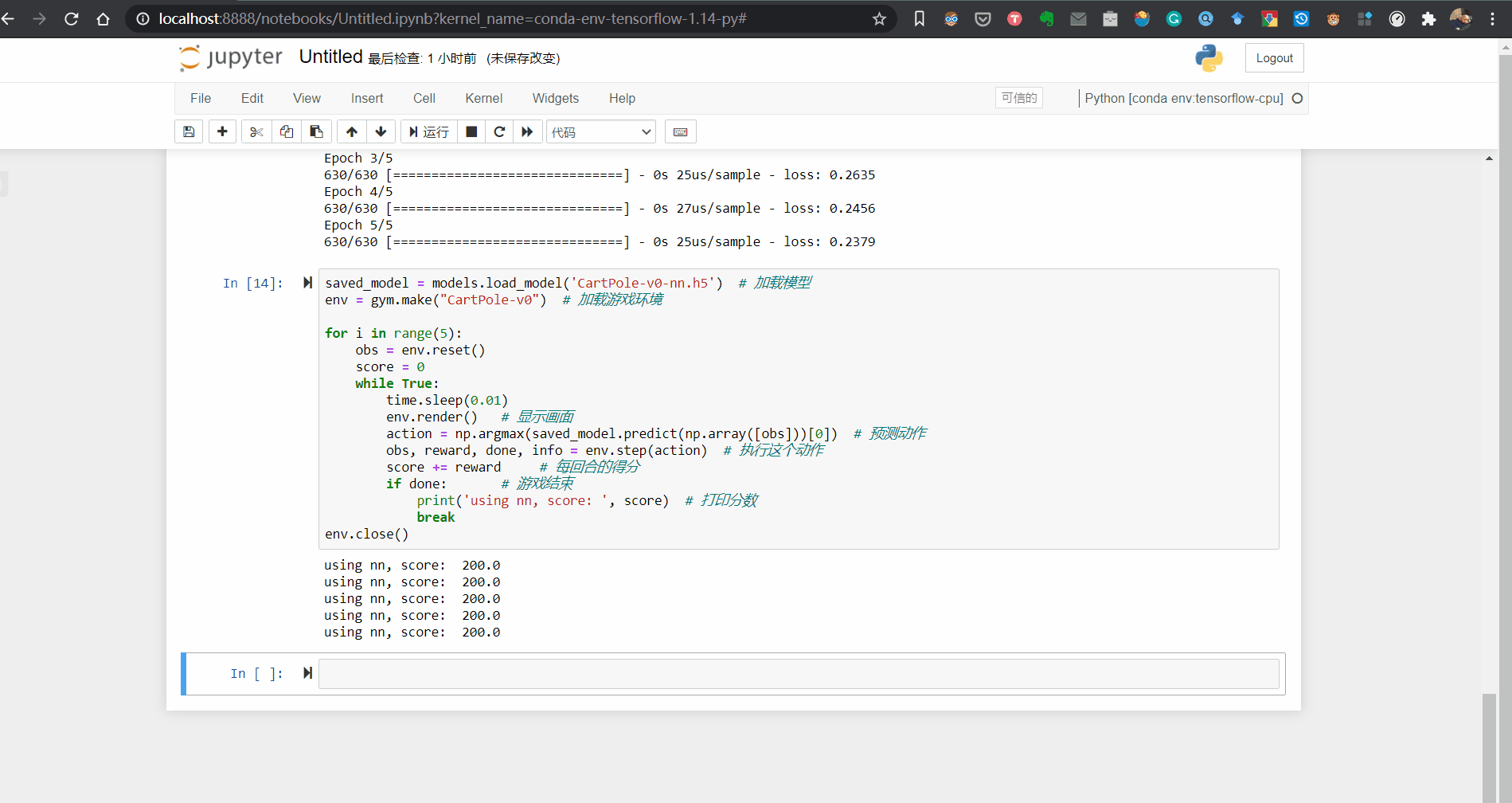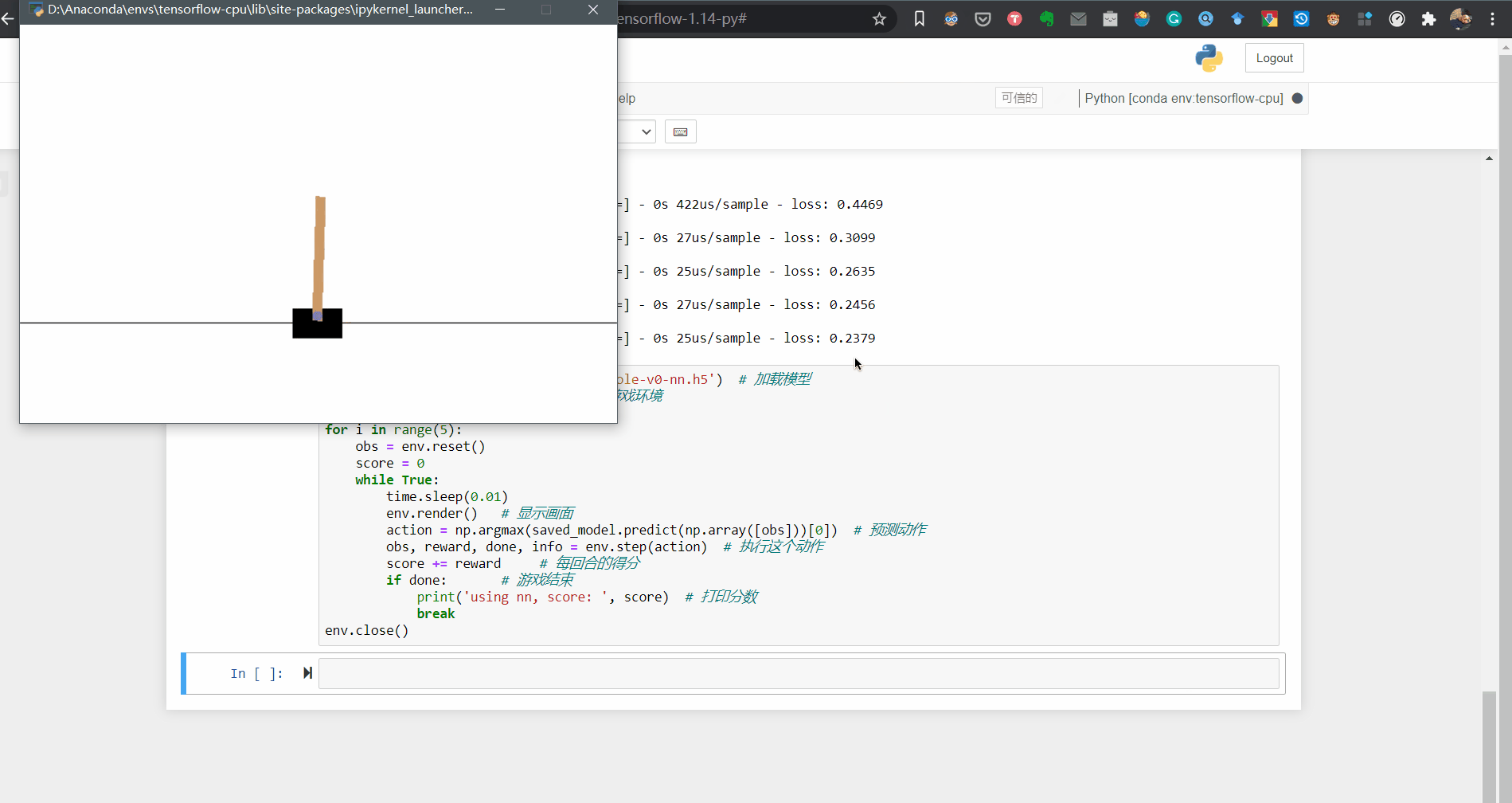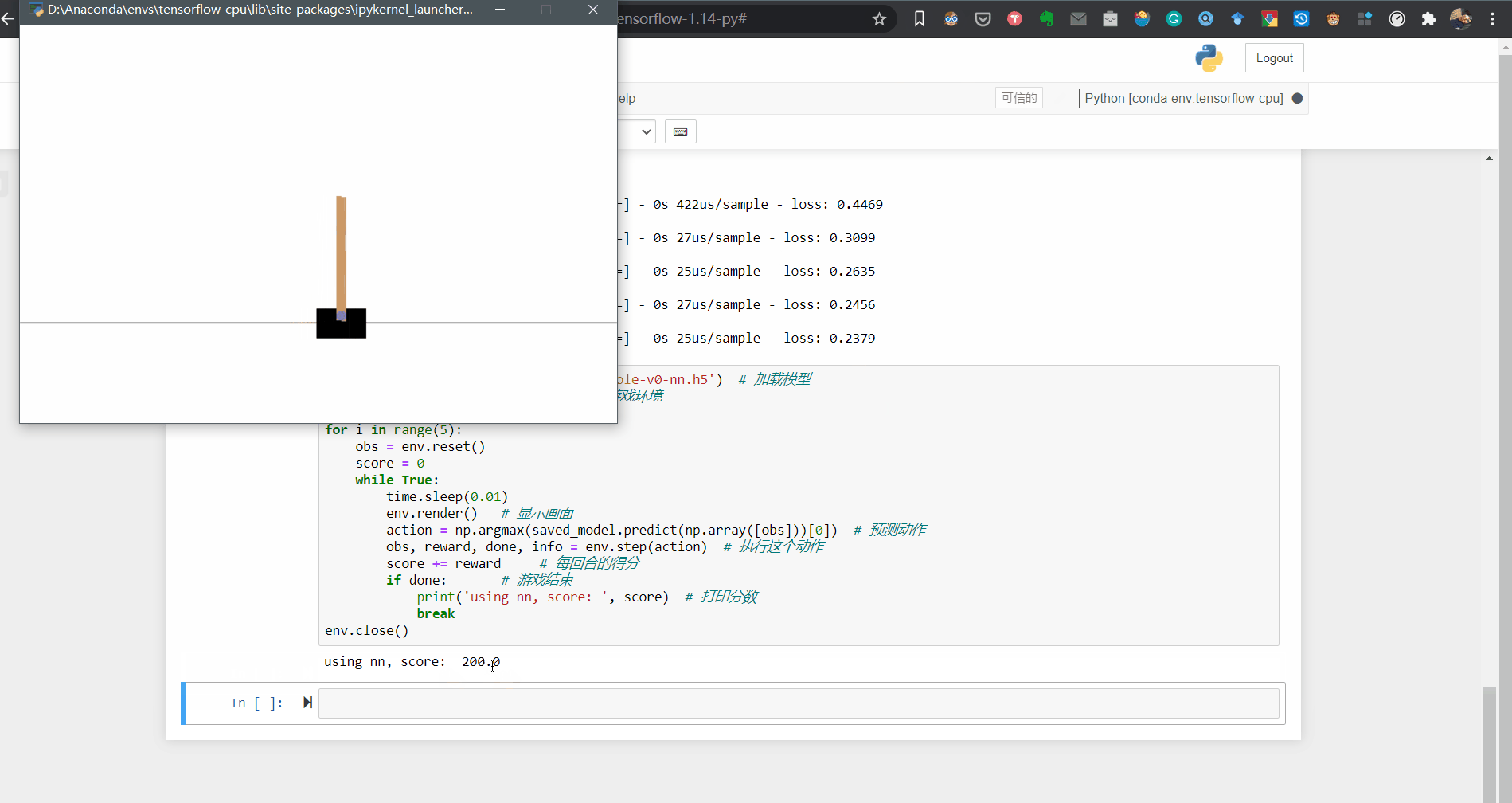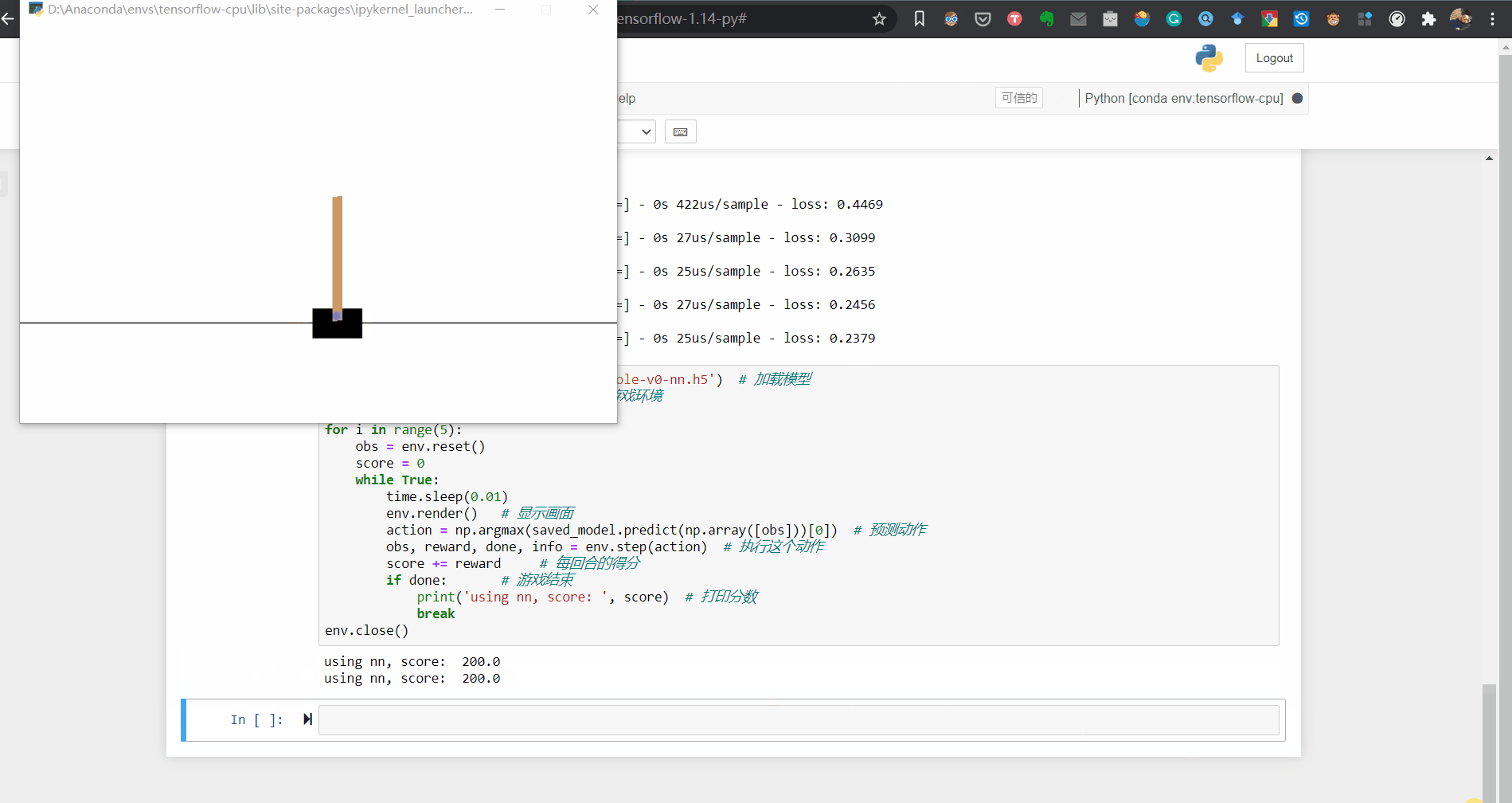
其实不只是DQN算法,PPO、A2C、A3C等算法在倒立摆这种简单得仿真环境下效果都很不错,可以利用倒立摆模型进行算法的学习,当然也可以选择动作和状态空间更为复杂的环境进行测试,这里给一些demo,可以参考博主的github仓库
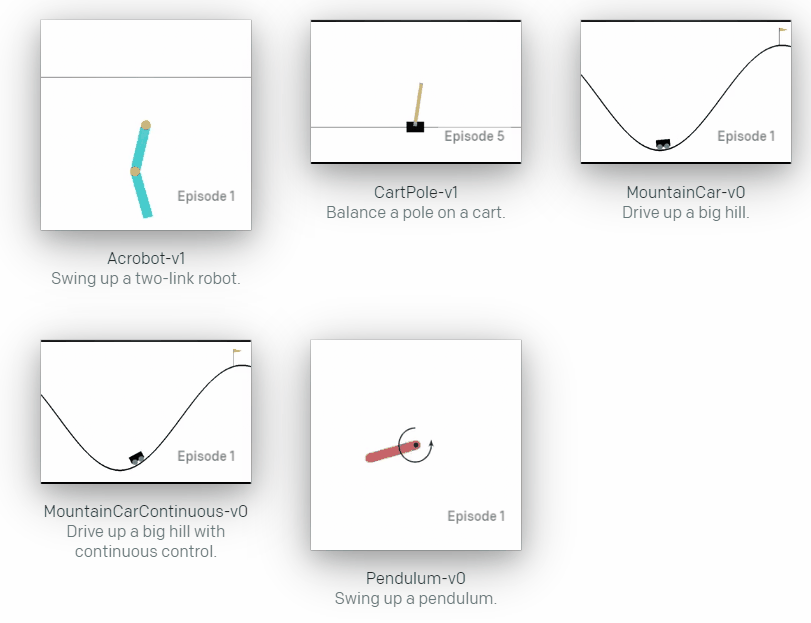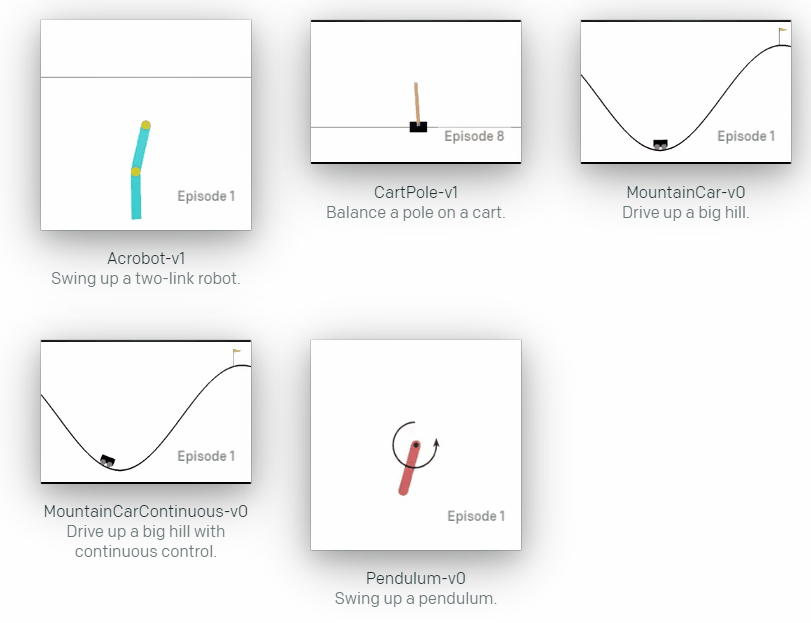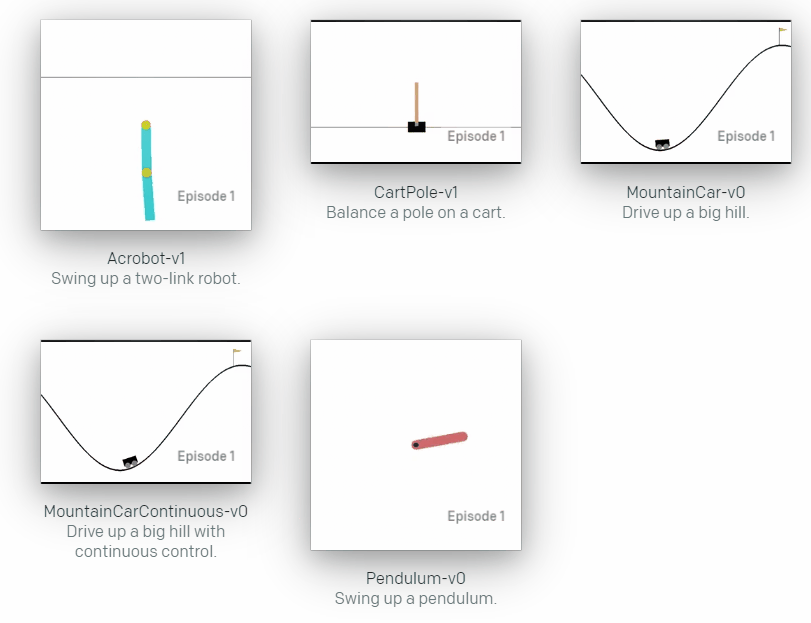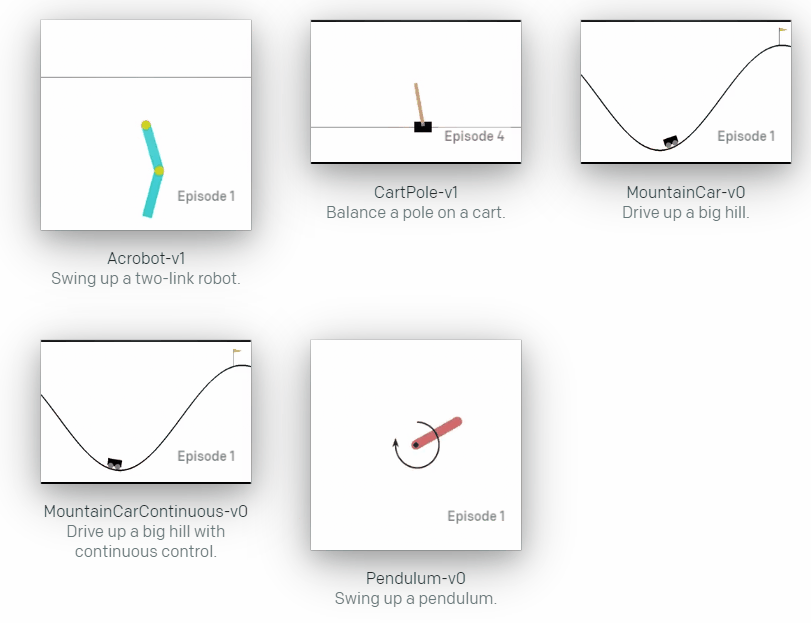
当然也有相对复杂一点的仿真环境,比如机械臂和机械手:
